It seems that we have to think about scalability, that what have be told us isn’t that true. Fast is the new small. People are spending a lot of time making thing faster and creating best practices in that field (such as the well-known Yahoo! exceptional performance team). A product has to have a lot of shinny features, to which you add a lot more every two months, and should keep the velocity of its early days. One path is to apply the simple rule: divide and conquer. Split every single piece of feature into a smaller ones, so this way you’ll be able to make it grow with Amdahl’s law in mind.
A simple example: you just built a micro blogging tool with your favorite tool. And created a simple REST API using a specify page in the same application, let’s say: /post/<user>/?message=<message>
It’s working and you can share piece of code between the front-end and the updater, like the model, some validators and so on. Now imagine that your service is becoming very popular, so you add servers and but them on a load balancer and use a memcached (or sharedance) to handle the users’ session. But the thing is that your API is becoming more popular than the front-end you’re using. 10 times more, like Twitter (lucky you). You cannot grow only the API part of your application because it’s tied to the web one, you’re screwed. And does a REST API need something that big and powerful that Apache is?
A single application must be split into smaller ones early. You may also run them on the same server at the beginning. I think that it makes the maintenance way simpler. You can know more clearly what are the dependencies.
The you can reduce the work load by postponing some tasks to later, or at least not in the time of the same request. Simple things like resizing images (i.e. local.ch’s binary pool, video presentation), sending notifications (email, Jabber/XMPP or even writing into the database). Any informations that the user don’t want to see directly can be done later and sometimes should. A way of doing this is to send a message over the wire and a worker will pick it up as soon as he has some free time (producer/consumer). There are many ways to do so, I recently (but it’s not something new) discovered lwqueue (written in Perl, with different wrappers), but you can go with Amazon’s SQS, Erlang copy ESQS, …
Your application is in different pieces (i.e. front end and API), it uses messaging to perform big (or not-that-urgent tasks) what remains? The data, because it takes time to write and read data. Especially when things become huge. So, I made a little test with SQLAlchemy on MySQL for a micro shouting tool where data are denormalized and tries to be a start for what’s called: database sharding.
User centric informations are stored into a common database but user related informations, in this case messages and relations (between users) are stored into a different database. From a user point of view, it only needs his database where everything is. There are a lot of data copied around, so it’s a trade-off between speed and space. It’s using a lot more space but you can grow very big and still have reasonable time while reading data because you’re in a specific space. With this architecture, if someone has 30’000 followers (like Robert Scoble), the message will be copied once 30’000 times but at read time you don’t have a sql query with 30’000 users. I don’t know how Twitter works, but identi.ca does sub select but a traditional (normalized) approach won’t work once it gets (too) big and your database will become the bottleneck.
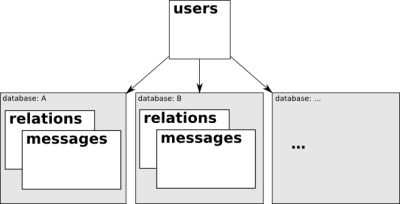
You can see in this little piece of code (output), apart the fact that I am still a n00b with SQLAlchemy, that the writing operations are complex because it has to be done in several places. I.e. with two users John(1) and Alice(1), that are in different databases db1 and db2, a subscription goes that way.
# John subscribes to Alice >>> subscribe(john, alice) # will run INSERT INTO db1.relations (from_id, to_id) VALUES (1, 2); INSERT INTO db2.relations (from_id, to_id) VALUES (1, 2);
The second statement (db2) can be done later, because only John(1) cares about it directly. Aline shouldn’t notice a delay if there is any.
# Alice sends a message >>> post(alice, "Hello World!") # the SQL statements INSERT INTO db2.messages (user_id, from_id, from_name, message) VALUES (2, 2, "Alice", "Hello World!"); # (can be done later) # select the followers SELECT from_id FROM db2.relations WHERE (to_id=2); # only one follower, John(1) INSERT INTO db1.messages (user_id, from_id, from_name, message) VALUES (1, 2, "Alice", "Hello World!");
Every single follower will get a carbon copy of the message, posting a message seems very complex, but now reading John’s messages are trivial:
SELECT from_name, message FROM db2.messages WHERE user_id=2;
No joins, no sub-selects, no hassle at read-time. It’s optimized for reading purposes. Writing takes a little more time, even if most of the actions can be postponed, and not when the user submits the data. The problem with this is that you spend a lot of time ensuring that data is coherent, but it’s not something urgent (for most of it).
It’s only a test, I’m not a DBA or a back-end guy, so it’s a very simple essay with bugs, glitches and design issues take this as is. This small experiments helped me understanding how you can, for example, design an application for Google App where JOINs don’t exist. And as you will see, SQLAlchemy great functionalities aren’t a great help here because I don’t know how to join model across schema or to have multiple databases into the same schema.
I invite you to watch, it you didn’t already video about how YouTube scaled so well and so fast.

{kind=link}
{kind=link}